本文主要介绍两种基本的数据归一化方法。
- min-max标准化(Min-Max Normalization)
- Z-score标准化方法
数据标准化(归一化)处理是数据挖掘的一项基础工作,不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。归一化方法主要有两种形式,一种是把数变为(0,1)之间的小数,一种是把有量纲表达式变为无量纲表达式。
下面是归一化和没有归一化的比较:
没有经过归一化,寻找最优解过程如下:
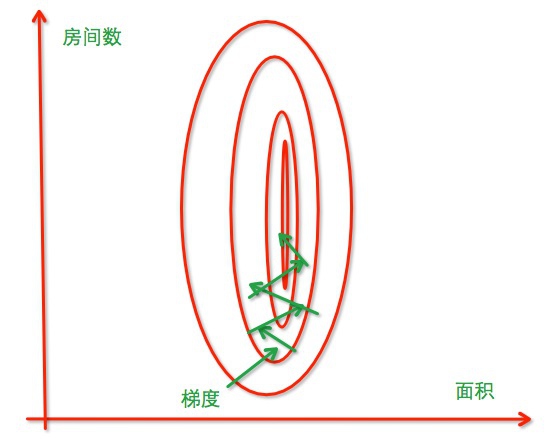
经过归一化,把各个特征的尺度控制在相同的范围内:
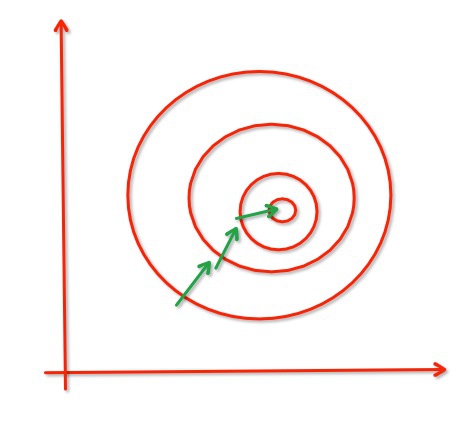
从经验上说,归一化是让不同维度之间的特征在数值上有一定比较性,可以大大提高分类器的准确性。
以下是两种常用的归一化方法:
1.min-max标准化(Min-Max Normalization)
也称为离差标准化,是对原始数据的线性变换,使结果值映射到[0 - 1]之间。转换函数如下:
$$x^{*}=\frac{x-x_{min}}{x_{max}-x_{min}}$$
x_min表示样本数据的最小值,x_max表示样本数据的最大值。
Python代码实现:
1 | def Normalization(x): |
测试:
1 | x=[1,2,1,4,3,2,5,6,2,7] |
Output:
1 | [0.0, 0.16666666666666666, 0.0, 0.5, 0.3333333333333333, 0.16666666666666666, 0.6666666666666666, 0.8333333333333334, 0.16666666666666666, 1.0] |
如果想要将数据映射到[-1,1],则将公式换成:
$$x^{*}=\frac{x-x_{mean}}{x_{max}-x_{min}}$$
x_mean表示数据的均值
Python代码实现:
1 | import numpy as np |
测试:
1 | x=[1,2,1,4,3,2,5,6,2,7] |
Output:
1 | [-0.3833333333333333, -0.21666666666666665, -0.3833333333333333, 0.1166666666666667, -0.049999999999999968, -0.21666666666666665, 0.28333333333333338, 0.45000000000000001, -0.21666666666666665, 0.6166666666666667] |
注意:上面的Normalization是处理单个列表的。
2.z-score标准化方法
这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1,转化函数为:
$$x^{*}=\frac{x-\mu}{\sigma}$$
其中,μ表示所有样本数据的均值,σ表示所有样本的标准差。
Python代码实现:
1 | import numpy as np |
测试:
1 | x=[1,2,1,4,3,2,5,6,2,7] |
Output:
1 | [-0.57356608478802995, -0.32418952618453861, -0.57356608478802995, 0.17456359102244395, -0.074812967581047343, -0.32418952618453861, 0.42394014962593524, 0.67331670822942646, -0.32418952618453861, 0.92269326683291775] |